
Backup is not Disaster Recovery
You probably already heard that RAID is not a backup. When world is ending and everything is burning, we also discover that a backup is not a Disaster Recovery plan. In this blog post I want to discuss why is so important to have an unplugged and reliable Disaster Recovery strategy.
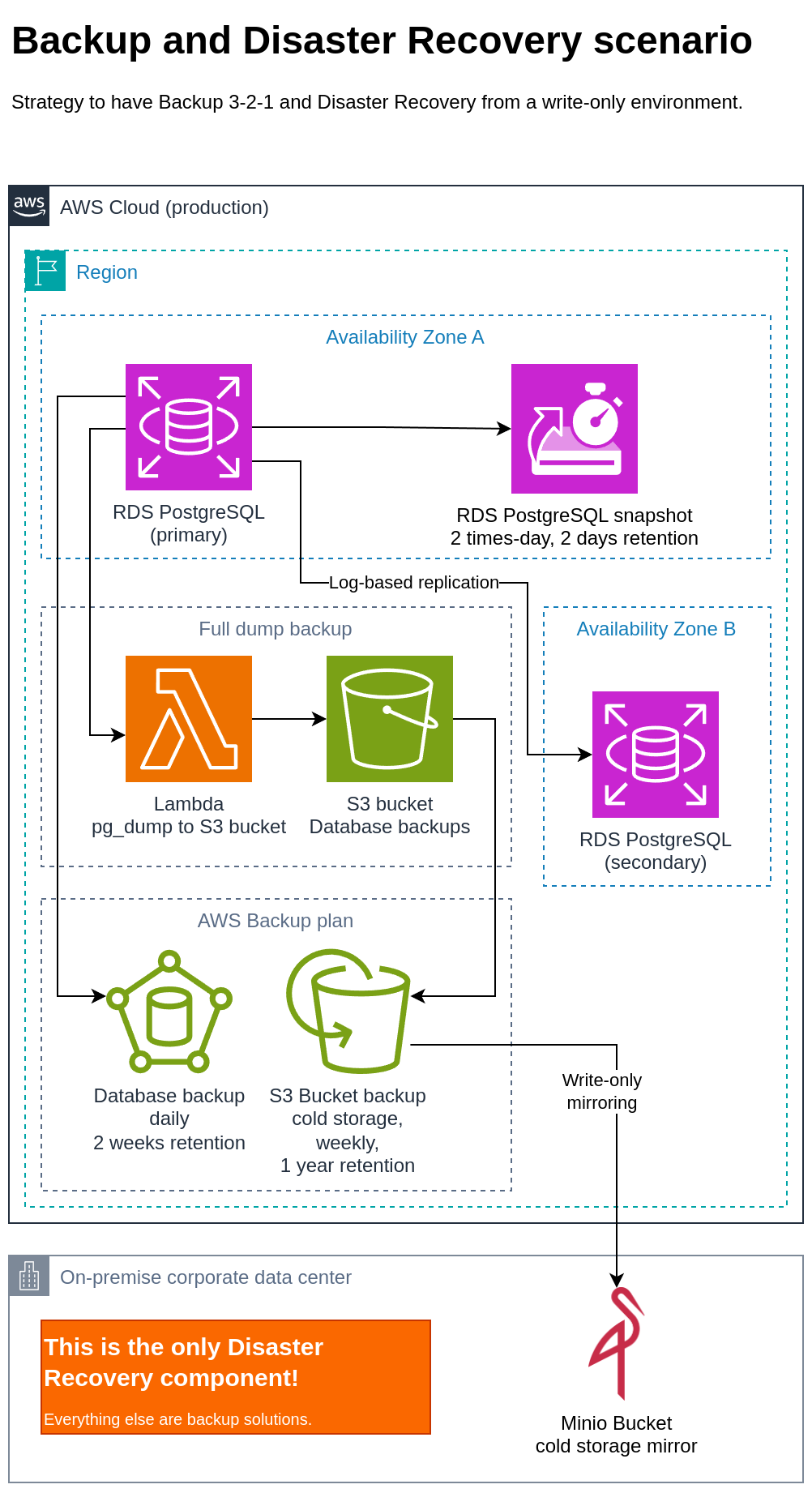
Common scenario for Backup plus Disaster Recovery
Let's start talking about the common differences between snapshots, backups, and Disaster Recovery strategies.
NOTE: this is not a recommended backup strategy for all scenarios. Ideally, the backup should follow at least the Backup 3-2-1 strategy and the one below doesn't have something equivalent to "different types of storage media", if you consider the AWS cloud provider as a type of storage media.
Assuming the following scenario:
- A primary PostgreSQL database, inside a single virtual machine.
- A secondary PostgreSQL database, inside a single virtual machine, being mirrored from the primary one via transaction logs.
- Each virtual machine have two snapshots per day (every 12 hours).
- A full database dump is daily generated and sent to an Object Storage system, like the AWS S3. This data is encrypted at rest and kept for 30 days.
- All the Object Storage system is mirrored to another one, in an on-premise storage via site-to-site VPN.
RAID is not a backup
I'm tired of talking about this and we already have a ton of resources about that. Do a 5min search about that.
Redundancy is also not a backup
In the example scenario, I added a primary and a secondary instances. The goal is to make sure things can still work if the primary instance is unavailable but this is not a backup. A corrupted data or data loss that happens in the relational database management system (RDBMS) will be propagated to both instances. You must have backup solutions despite your redundant systems.
Redundancy scenarios:
- Replica primary-secondary:
- If the original environment is down, like a long power outage or broken fiber-optical cable, it is possible to switch to the secondary instance. Usually, the data loss is nothing but a few seconds before the primary region goes down. This can be a great compromise if your business allows this kind of data loss.
Backup data restoration
These are predicted scenarios of data recovery/restoration. The "predicted" is the biggest difference between a backup and a Disaster Recovery but we will talk about that later.
Here, if you came from a corporate environment, you will disagree with me because everyone has a different opinion about it. So, for this post sake, I'm assuming:
- If you plan anything, it is a backup, not a Disaster Recovery.
- Anything you plan to restore, I'm calling backup data restoration. Including full machines data.
- If you have any metrics, it is a backup, not a Disaster Recovery.
Data recovery scenarios:
- Log restoration (seconds precision):
- Some databases, like PostgreSQL, allows you to undo transactions based on the logs records. In practice, this allows you to go back in time with extremely precision if you enough log data. For example, if you have log data of the past day, you can recover everything to a specific Point-In-Time from a day ago. This configuration you must set in the database itself and use its own tooling to set the retention size and perform a restoration.
- Snapshot restoration (up to 12h precision, from up to 2 days ago):
- If something goes wrong with the application and the database is corrupted, it is possible to use the snapshot to recover the data from a few hours ago. This is a great strategy to have a faster way to recover data, since a few gigabytes of delta-data can be restored in a few minutes.
- Full dump restoration (up to 24h precision, from up to 30 days ago):
- This is the most bare-bones and agnostic way to perform a restoration. If you need to recreate a new database from a backup data, this is the most straightforward and easy way to do that. The drawback is how long it will take to restore and how big is the dump since, since each dump with contain a full database copy. If you have a massive database, this can take a long time, even days for multi-terabyte database, and it will cost more to store all dumps.
- Full dump restoration from archive (up to 7 days precision, from up to 1 year ago):
- Same as the one above. This is important when you realized you made a mistake after a few months. I hope you never need this.
Ok, so we cover all the scenarios where we restore data from a backup. But what about a Disaster Recovery? What are the differences?
What is a Disaster Recovery plan?
A Disaster Recovery plan is the last resort. Something you plan to never use. All backup strategies must NOT assume the Disaster Recovery plan existence.
The goal is to have something to save the customer (maybe even your company) if everything goes wrong.
There are a few conditions I want to match, in a mix of what I see in corporate environments and my own opinion:
- The disaster recovery destination must be write-only. It must be impossible to delete the disaster recovery content from the source environment.
- Do not trust automation. Do not use any type of SSO federation. Do not integrate any type of bot. If you have an automation being compromised or simply buggy, it should never reach the disaster recovery environment.
- Validate your disaster recovery content every few months. You must make sure you are recording data that is able to be restored.
- If possible, do not set your disaster recovery environment in the same place as the production one. So, for example, if your main application works inside the AWS cloud, you should have your data being exported to another cloud provider like Google Cloud or Microsoft Azure, or even your on-premise environment like the one I gave in the example above. The goal is to never trust in a single vendor.
So, in summary, a Disaster Recovery plan is:
- Last resort: all your backup plans should never assume this exists.
- Full dumps: a copy of everything you need to recover your business if things blow up.
- Comprehensive: be obvious when storing and naming things. Even when the world is not ending people don't like acronyms.
- Write-only: the place where you store that data must be totally disconnected from the production environment. If possible, should even be physically disconnected when there's no data in transit.
- Zero automation: where you do not trust automation. Never, never, never integrate any automation or federation to anything related to a Disaster Recovery plan.
Conclusion
A Disaster Recovery plan is the last resort in a company. Most of this post I covered what a backup strategy is and the Disaster Recovery was a little piece compared to that.
It must be simple to understand and retrieve its content.
And I really hope you never need what you've learned today.
References
- Explaining Computers: Data Backup: The 3-2-1 Rule
https://www.youtube.com/watch?v=rFO6NyLIP7M - Scaling Postgres: PostgreSQL Backup & Point-In-Time Recovery
https://www.youtube.com/watch?v=Jvdtx-Smffo